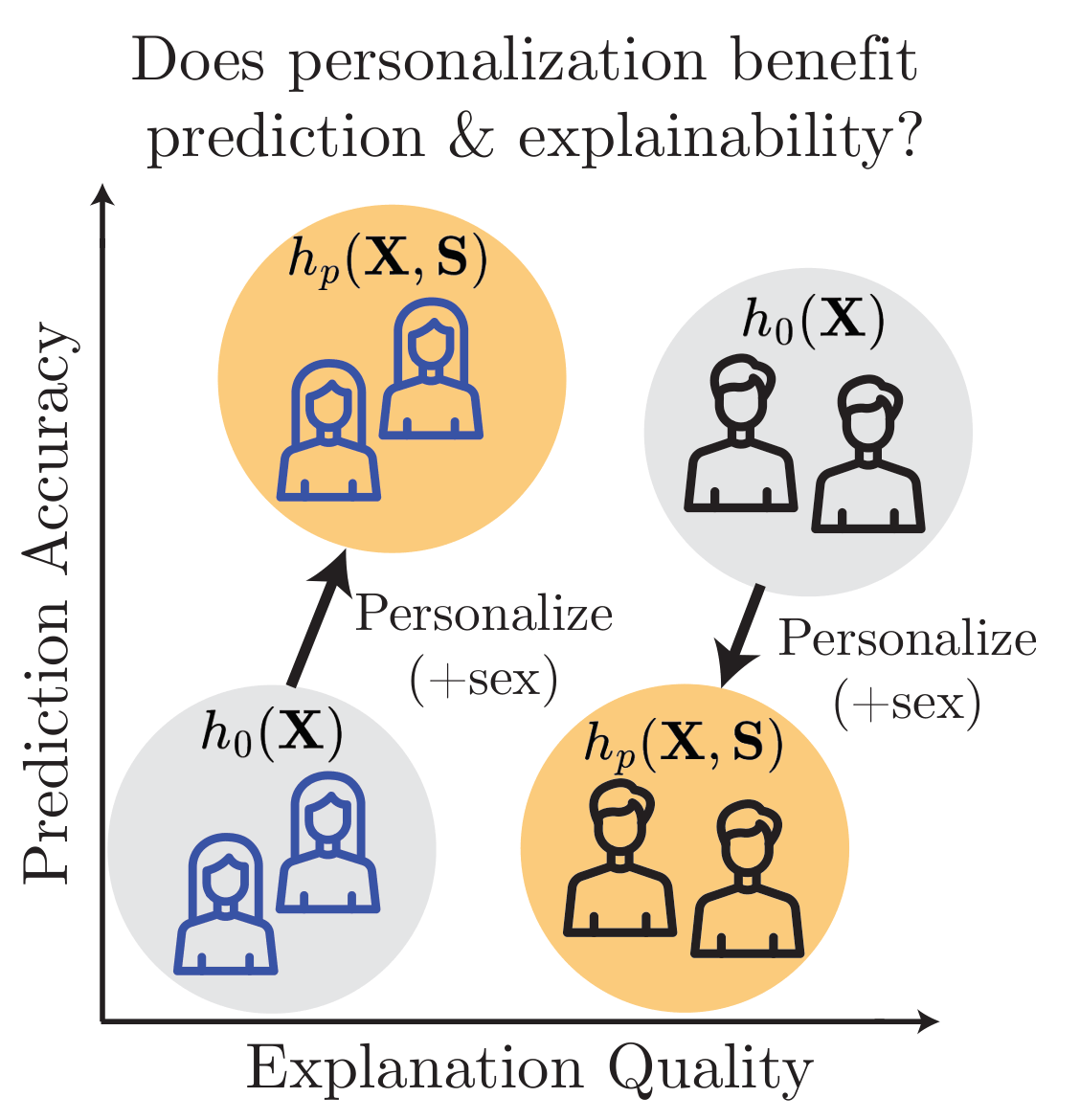
Theoretical Findings: Impact of Personalization on Prediction and Explainability
This paper provides the first formal analysis showing that personalization's effect on prediction does not determine its effect on explainability, highlighting the need to evaluate both. A common intuition in machine learning is that if personalization improves prediction, it should also improve the quality of explanations derived from the model. Despite its prevalence, this presumed connection between predictive performance and explanation quality has not been formally analyzed in the context of personalization.
We consider a generic model $h_0 : \mathcal{X} \to \mathcal{Y}$ and a personalized model $h_p : \mathcal{X} \times \mathcal{S} \to \mathcal{Y}$, and measure the Group Benefit of Personalization $\GBoP(h_0, h_p, s) = C(h_0, s) - C(h_p, s)$ for each group $s \in \mathcal{S}$, where a positive value indicates the personalized model performs better. We write $\gamma_P$ and $\gamma_X$ for the worst-case group benefit over prediction and explanation, respectively.
No Prediction Benefit Does Not Imply No Explainability Benefit
The following theorem shows that a personalized model may match a generic model in accuracy, yet offer better explanation. Focusing only on prediction can overlook significant interpretability gains.
Theorem 4.1
There exists a data distribution $P_{\mathbf{X}, \mathbf{S}, \mathbf{Y}}$ such that the Bayes optimal classifiers $h_0$ and $h_p$ satisfy $\gamma_P(h_0, h_p) = 0$ (with $\gamma_P$ measured by 0-1 loss) and $\gamma_X(h_0, h_p) > 0$ (with $\gamma_X$ measured by sufficiency and incomprehensiveness).
Example 4.1
Consider a loan approval model using credit score, income, and debt-to-income ratio. Adding a personal feature—"pre-approved by another bank"—that is strongly correlated with existing features may leave predictions unchanged. However, an explainer might now assign most importance to this new feature because it provides a clearer justification. Thus $\GBoP_P = 0$ but $\GBoP_X > 0$ for each group.
No Prediction Harm Does Not Imply No Explainability Harm
A personalized model may match a generic model in accuracy yet offer worse explanations. Focusing only on predictive performance can obscure significant harms to explainability.
Theorem 4.2
There exists a data distribution $P_{\mathbf{X}, \mathbf{S}, \mathbf{Y}}$ such that the Bayes optimal classifiers $h_0$ and $h_p$ satisfy $\gamma_P = 0$ (with $\gamma_P$ measured by 0-1 loss) and $\gamma_X < 0$ (with $\gamma_X$ measured by incomprehensiveness).
Example 4.2
Consider a pneumonia detection model whose chest X-ray findings alone perfectly predict outcomes. Adding white blood cell count leaves accuracy unchanged, but the personalized model now splits importance between X-ray findings and white blood cell count. The explanation is worse—it is less clear which feature drives the decision—even though the X-ray alone was already perfectly predictive.
Personalization Can Affect Groups Differently
Even when no group's prediction changes, personalization may improve explainability for some groups while simultaneously degrading it for others.
Theorem 4.3
There exists a data distribution $P_{\mathbf{X}, \mathbf{S}, \mathbf{Y}}$ such that the Bayes optimal classifiers $h_0$ and $h_p$ satisfy $\GBoP_{P}(h_0, h_p, s) = 0$ (measured by 0-1 loss) for all groups $s$, but some groups have $\GBoP_{X}(h_0, h_p, s) > 0$ while others have $\GBoP_{X}(h_0, h_p, s) < 0$ (measured by sufficiency and incomprehensiveness).
No Explainability Benefit Can Imply No Prediction Benefit (Additive Setting)
We now ask the converse: can a lack of explainability benefit imply no predictive benefit? We show this is true for a simple additive model, as long as both sufficiency and incomprehensiveness show no benefit.
Theorem 4.4
Assume $h_0$ and $h_p$ are Bayes optimal regressors and $P_{\mathbf{X}, \mathbf{S}, \mathbf{Y}}$ follows an additive model: $$\mathbf{Y} = \alpha_1 \mathbf{X}_1 + \cdots + \alpha_t \mathbf{X}_t + \alpha_{t+1} \mathbf{S}_1 + \cdots + \alpha_{t+k} \mathbf{S}_k + \epsilon,$$ where $\mathbf{X}_1, \ldots, \mathbf{X}_t$ and $\mathbf{S}_1, \ldots, \mathbf{S}_k$ are independent and $\epsilon$ is independent noise. If for $s \in \mathcal{S}$: $$\GBoP_{\text{suff}}(h_0, h_p, s) = \GBoP_{\text{incomp}}(h_0, h_p, s) = 0,$$ then $\GBoP_P(h_0, h_p, s) = 0$. Consequently, if this holds for all groups $s$, then $\gamma_P = 0$.
Corollary 4.5
Under the assumptions of Theorem 4.4, if for some $s \in \mathcal{S}$ we have $\GBoP_P(h_0, h_p, s) \neq 0$, then it also holds that $\GBoP_{\text{suff}}(h_0, h_p, s) \neq 0$ or $\GBoP_{\text{incomp}}(h_0, h_p, s) \neq 0$. In other words, if personalization affects prediction, it must also affect explanation for at least one measure and one demographic group.
This result establishes a rare direct link between explanation and prediction—in the simplified linear setting. Whether the link holds for general models remains an open question.